HashTable 是什么?
之前详细介绍过 HashMap 的原理,HashTable 与 HashMap 用法一样,都是 key-value 结构,底层的实现都差不多,最大的区别是, HashTable 是线程安全的,HashMap 不是线程安全的。
为什么需要线程安全?
我们知道,HashMap 的底层数据结构是数组 + 链表 + 红黑树,当两个元素都落在数组的同一个位置时,会形成链表,如果两个线程分别同时 put 这个元素,一个元素把另一个元素覆盖了,就会导致数据丢失。所以我们需要同时只有一个线程能 put 元素,也就是线程安全。
HashTable 如何解决线程安全问题的?
HashTable 解决线程安全问题非常简单粗暴,就是在方法前加 synchronize 关键词,HasTable 不仅给写操作加锁 put remove clone 等,还给读操作加了锁 get, 如下:
public synchronized V get(Object key)
public synchronized V put(K key, V value)
public synchronized boolean remove(Object key, Object value)
虽然实现起来比较简单,但效率不高。我们一般选用 ConcurrentHashMap.
为什么 ConcurrentHashMap 的效率高
- ConcurrentHashMap 没有大量使用
synchronsize这种重量级锁。而是在一些关键位置使用乐观锁(CAS), 线程可以无阻塞的运行。 - 读方法没有加锁
- 扩容时老数据的转移是并发执行的,这样扩容的效率更高。
Java8 中 ConcurrentHashMap 基于分段锁+CAS 保证线程安全,分段锁基于 synchronized 实现,它仅仅锁住某个数组的某个槽位,而不是整个数组
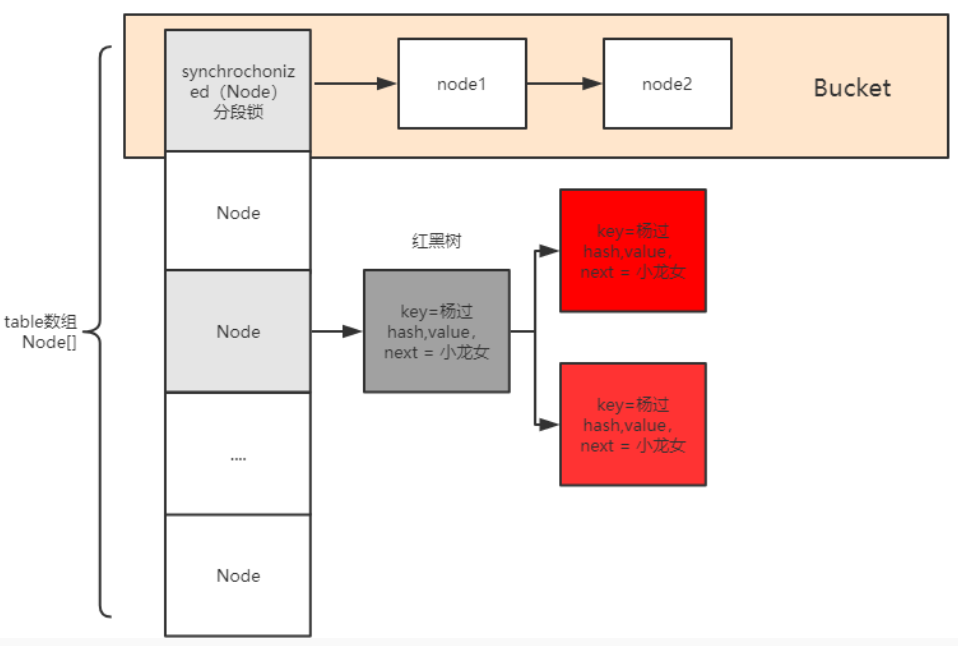
CAS
分段锁
ConcurrentHashMap 重点成员变量
-
LOAD_FACTOR: 负载因子, 默认 75%, 当 table 使用率达到 75%时, 为减少 table 的 hash 碰撞, tabel 长度将扩容一倍。负载因子计算: 元素总个数%table.lengh
-
TREEIFY_THRESHOLD: 默认 8, 当链表长度达到 8 时, 将结构转变为红黑树。
-
UNTREEIFY_THRESHOLD: 默认 6, 红黑树转变为链表的阈值。
-
MIN_TRANSFER_STRIDE: 默认 16, table 扩容时, 每个线程最少迁移 table 的槽位个数。
-
MOVED: 值为-1, 当 Node.hash 为 MOVED 时, 代表着 table 正在扩容
-
TREEBIN, 置为-2, 代表此元素后接红黑树。
-
nextTable: table 迁移过程临时变量, 在迁移过程中将元素全部迁移到 nextTable 上。
-
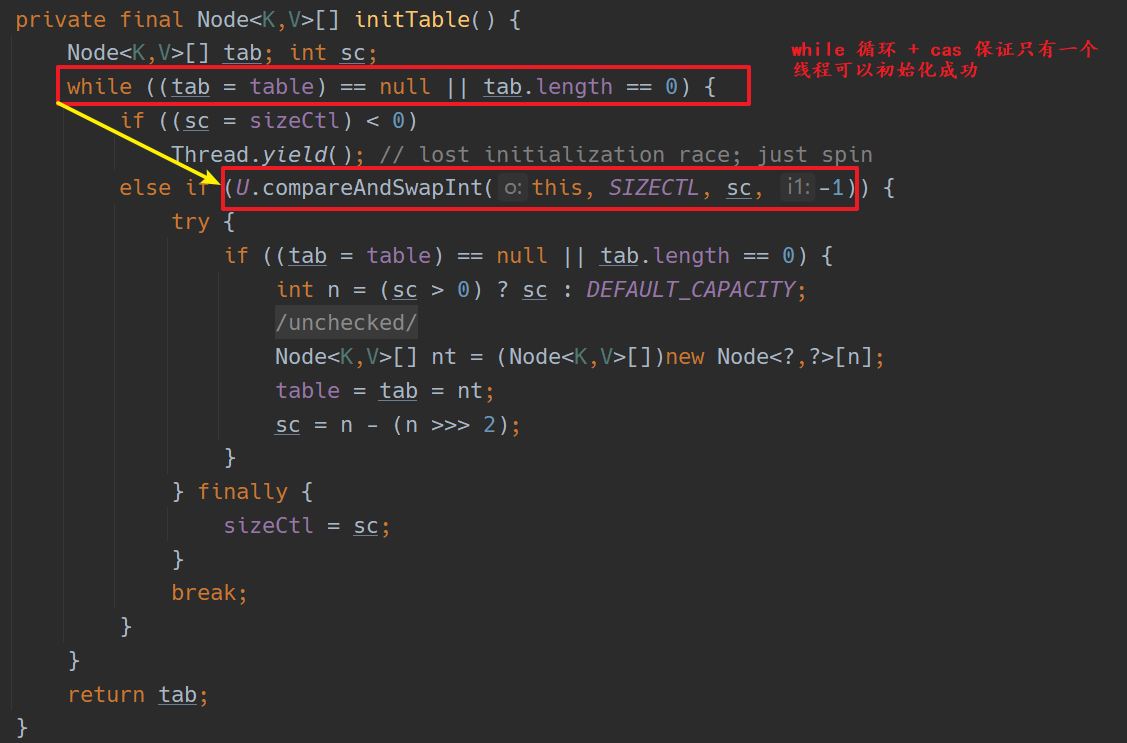
sizeCtl: 用来标志 table 初始化和扩容的, 不同的取值代表着不同的含义:
- 0: table 还没有被初始化
- -1: table 正在初始化
- 小于-1: 实际值为 resizeStamp(n) «RESIZE_STAMP_SHIFT+2, 表明 table 正在扩容
- 大于 0: 初始化完成后, 代表 table 最大存放元素的个数, 默认为 0.75*n
-
transferIndex: table 容量从 n 扩到 2n 时, 是从索引 n->1 的元素开始迁移,
-
transferIndex 代表当前已经迁移的元素下标
-
ForwardingNode: 一个特殊的 Node 节点, 其 hashcode=MOVED, 代表着此时 table 正在做扩容操作。扩容期间, 若 table 某个元素为 null, 那么该元素设置为 ForwardingNode, 当下个线程向这个元素插入数据时, 检查 hashcode=MOVED, 就会帮着扩容
ConcurrentHashMap 重点方法解释
初始化
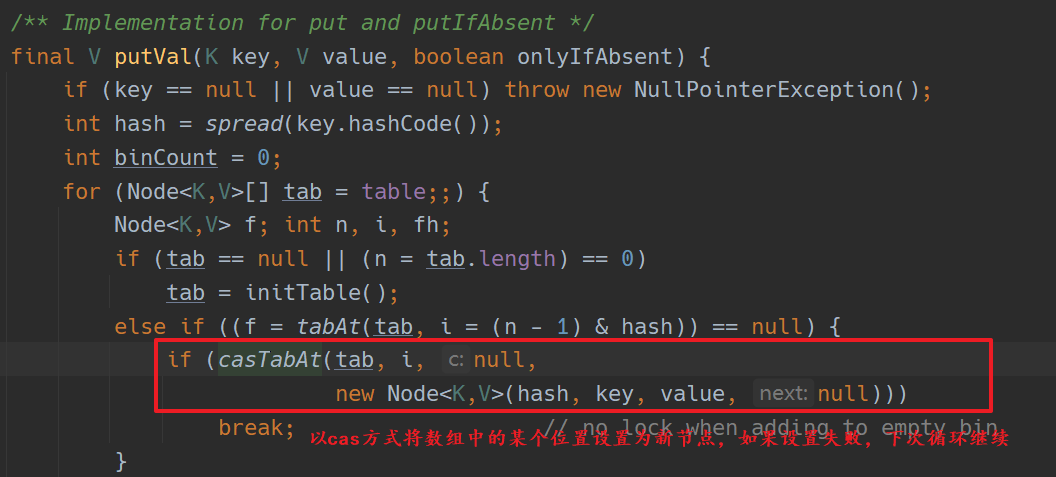
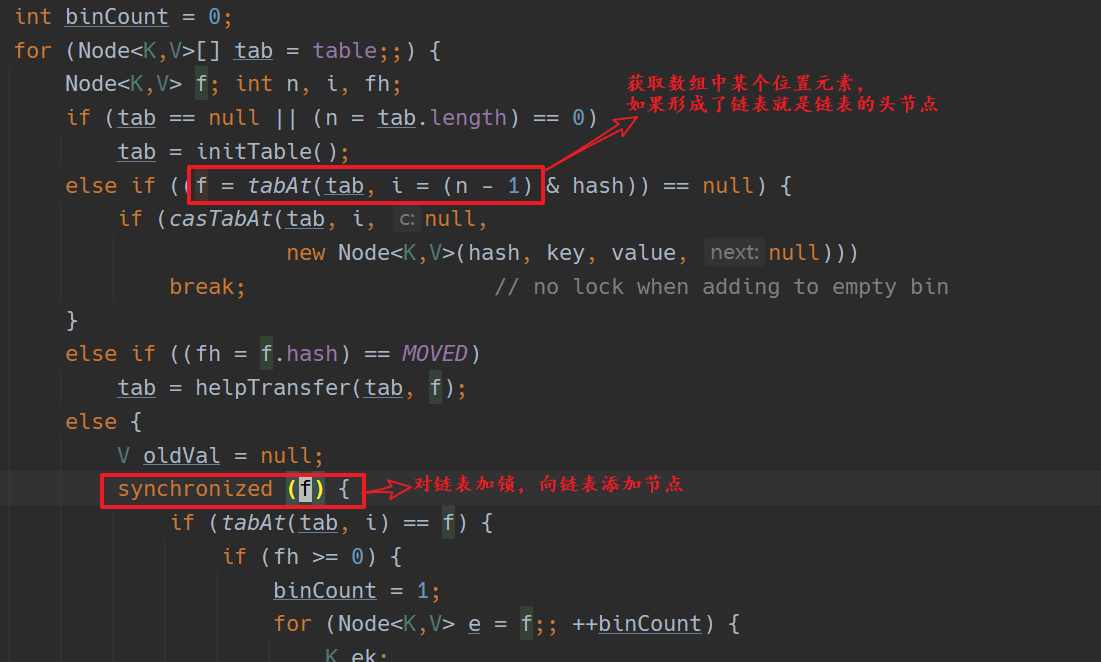
put 数据
cas 锁定单个槽位
锁住某个链表
协助扩容
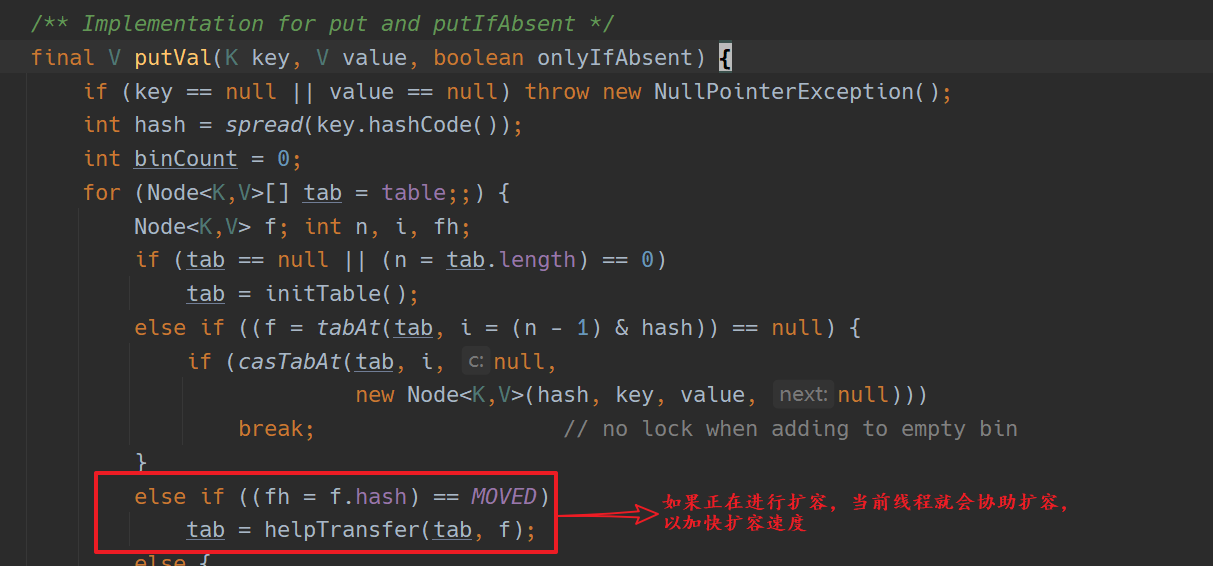
上图只是协助扩容的时机,至于协助扩容内部执行的详细步骤比较复杂,牵涉一些位运算,不再详细探究了,大致做了一下几件事:
- 定线程每轮迁移元素的个数 stride, 比如进来一个线程, 确定扩容 table 下标为 (a,b]之间元素, 下一个线程扩容(b,c]。这里对 b-a 或者 c-b 也是由最小值 16 限制的。也就是说每个线程最少扩容连续 16 个 table 的元素。而标志当前迁移的下标保存在 transferIndex 里面。
- 检查 nextTab 是否完成初始化, 若没有的话, 说明是第一个迁移的线程, 先初始化 nextTab, size 是之前 table 的 2 倍。
- 进入 while 循环查找本轮迁移的 table 下标元素区间, 保存在(bound, i]中, 注意这里是半开半闭区间。
- 从i -> bound开始遍历table中每个元素, 这里是从大到小遍历的:
- 若该元素为空, 则向该元素标写入ForwardingNode, 然后检查下一个元素。 当别 的线程向这个元素插入数据时, 根据这个标志符知道了table正在被别的线程迁移, 在 putVal中就会调用helpTransfer帮着迁移。
- 若该元素的hash=MOVED, 代表次table正在处于迁移之中, 跳过。 按道理不会跑着这里的。
- 否则说明该元素跟着的是一个链表或者是个红黑树结构, 若hash>0, 则说明是个链 表, 若f instanceof TreeBin, 则说明是个红黑树结构。
- 链表迁移原理如下: 遍历链表每个节点。 若节点的(f.hash&n == 0) 成立, 则将节 点放在i, 否则, 则将节点放在n+i上面, 这一点和之前讲解的 HashMap 没有变化